欧宝app(中国) 用 AI 写规格、国内大模子作念推理: 一百块能否搭降坐蓐级 RAG?

当AI代码生成遇上国内LLMAPI,一场的确的坐蓐级RAG实验给出了谜底。从ClaudeCode生成的440行有策动文档启航,到集成通义千问API、开拓14个隐私Bug,最终仅销耗100元东说念主民币就搭建起包含羼杂检索、景色机管说念和企业级前端的全栈系统。本文将揭秘架构选型、中枢数据样例与上线前自查清单,为评估AI代码生成+国内大模子落地的团队提供实战参考。
本文记载一次无缺实验:先用ClaudeCode生成约440行的杀青有策动文档,再据此逐模块生成Monorepo代码,启动时调用阿里百真金不怕火通义千问(对话qwen3.6-plus、向量text-embedding-3-large),全链路API销耗约100元东说念主民币。系统包含多花式文档入库、Milvus羼杂检索、LangGraph十节点景色机、评测面板与企业级前端,共开拓14个Bug——其中普遍进展为「静默失败」而非明确报错。
若你正在评估「AI生成代码+国内LLMAPI」道路是否可行,本文重心提供:架构选型逻辑、中枢数据样例、判定与阈值规矩、四条典型场景演练,以及上线前自查清单,便于对照自家环境与预行为念决策。
一、问题配景:为什么要把「资本」和「踩坑」写清爽
企业里面文档问答、客服学问库、合规手册检索——场景不同,工夫旅途却高度雷同:分解文档、切块、向量化、检索、生成、带起原援用。立项时,业务方常问三个问题:
要花若干钱?Embedding批量写入、多轮对话测试、Rerank调用,Token消耗不透明。
要多久能上线?若依赖国际模子与默许SDK示例,国内API兼容、向量维度、雷同度阈值等细节会拖慢历程。
2026世界杯预选赛下单中国体彩官网AI写代码靠不靠谱?若惟有Demo级能力,空泛评测、可不雅测性与工程化,仍无法称为「坐蓐级」。
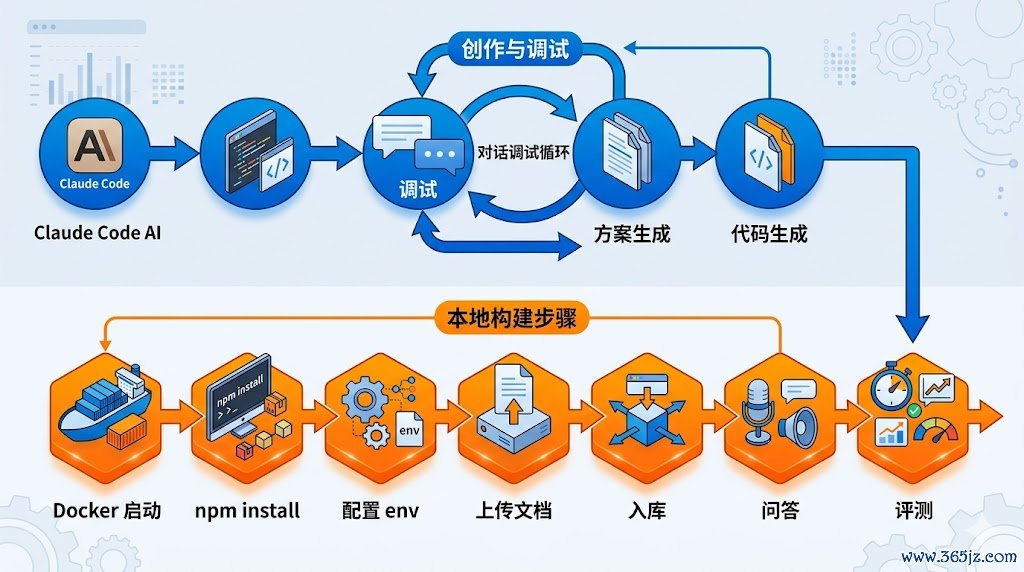
本次实验的标的因此很明确:不是作念一个能跑通的Demo,而是实测从零完成一套带评测与可不雅测性的RAG平台,究竟消耗若干Token、会碰到哪些典型故障。开发方式聘请「先写规格、再生成代码」:ClaudeCode产出施工蓝图hashed-gliding-metcalfe.md,再据此生成Monorepo、Docker、前后端与LangGraph活水线;模子侧谐和走阿里百真金不怕火OpenAI兼容接口。

二、委派鸿沟:这个相貌到底委派了什么
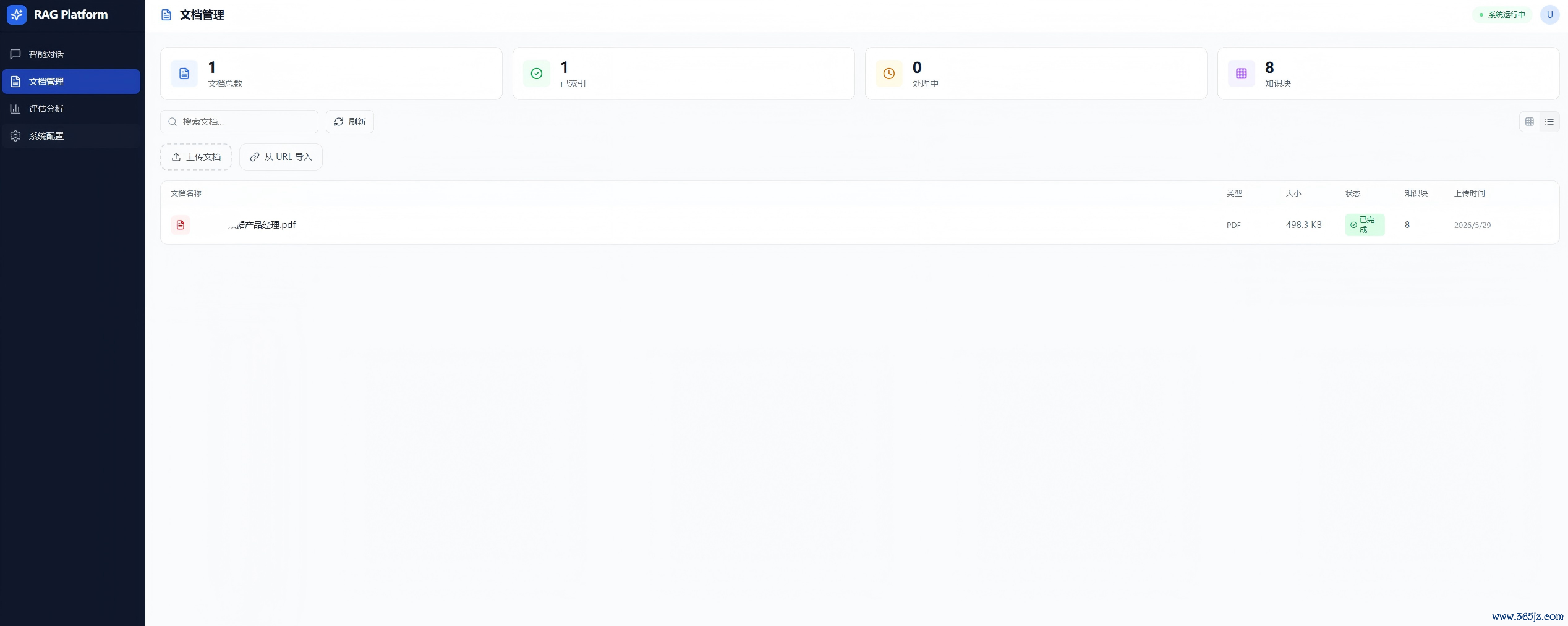
产物定位:坐蓐级RAG平台——用户上传PDF、Word、Excel、HTML、Markdown,系统自动分解、分块、向量镶嵌、索引存储,通过对话界面进行基于文档内容的智能问答,并附带援用起原。
不在本期领域(或后续优化):
MinHash+LSH高档去重(因minhash包弃用,暂用内容哈希替代)
坐蓐环境Nginx与无缺CI/CD(文档侧重腹地构建与调试旅途)
中枢委派物:
有策动文档:hashed-gliding-metcalfe.md(约440行),含架构、目次树、LangGraph节点、API与数据模子
后端:Node.js+Fastify5+LangGraph十节点DAG+SSE流式反映
前端:Vite+React19+TailwindCSS4,四面板(对话、文档、评估、设立)
基础方法:Milvus2.5.x(闹热+BM25寥落)、PostgreSQL16、Redis7、Attu管制界面
可不雅测与评测:掷中率、MRR、针织度、关连性等策动面板
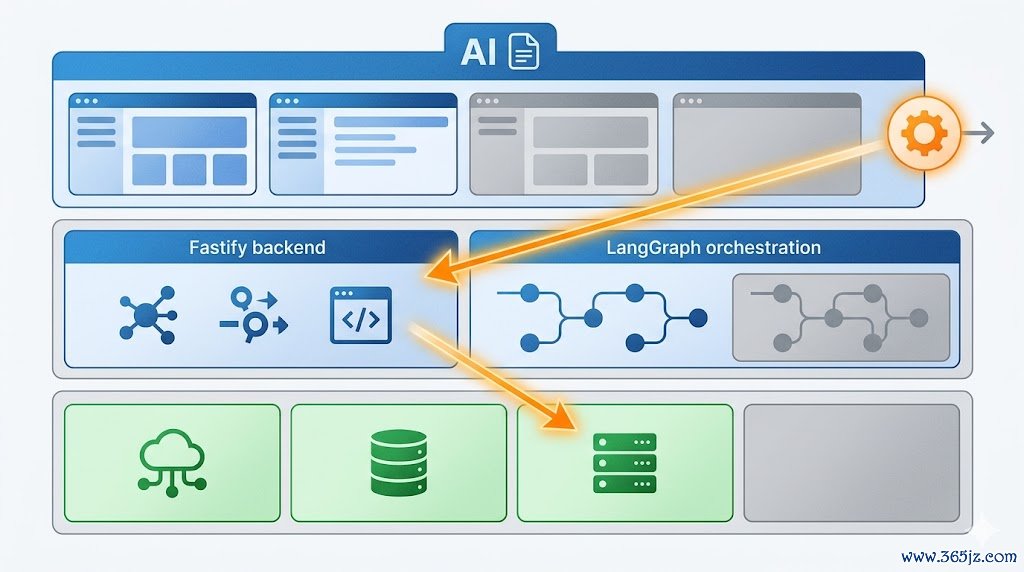
三、系统底盘:「从Markdown编译出代码」的两段式开发
传统开发是边念念边写;本次实验聘请规格驱动+AI生成:
第一段:生成施工蓝图
在创建任何代码文献之前,ClaudeCode先输出hashed-gliding-metcalfe.md,内容包括:
坐蓐级RAG架构与Monorepo目次办事
LangGraph十节点景色机(查询分类、HyDE、羼杂检索、Rerank、自阅兵等)
入库活水线(多花式分解→语义分块→Milvus羼杂索引)
API路由与分享类型界说
第二段:按有策动逐模块生成代码
以有策动文档为独一规格证据,生成packages/backend、packages/frontend、packages/shared,并在腹地启动报错时通过对话逐条开拓。
腹地构建链路(用户侧实际):
dockercomposeup-d—启动Milvus、PostgreSQL、Redis、Attu
npminstall—装配workspaces依赖
设立.env—填入通义千问APIKey与模子名
npmrundev—Turbo并行启动后端:3000与前端:5173
上传文档→入库活水线→对话问答→评测面板调参
工夫栈分层:
前端(5173):Vite+React19+TypeScript+TailwindCSS4,Zustand+ReactQuery
后端(3000):Fastify5+LangGraph,Zod设立校验,SSE流式
存储与外部API:Milvus闹热1024维+BM25寥落向量;PostgreSQL存元数据;Redis缓存与限流;阿里百真金不怕火提供LLM与Embedding
四、要害能力拆解
4.1多花式文档入库
聘请分解器工场模式:PDF(pdf-parse)、DOCX(mammoth)、Excel(xlsx转CSV文本)、HTML(cheerio+turndown)、Markdown(保留标题元数据)。分块策略可按文档类型路由:Markdown按标题层级、语义鸿沟、父子结构或固定大小。
想象意图:企业文档花式混杂,谐和工场+策略路由幸免为每种花式写死一条活水线,便于后续膨胀。
4.2Milvus羼杂索引
集合字段包含:document_id(分区键)、content、dense_vector(1024维)、sparse_vector(BM25)、chunk_index、metadataJSON,以及doc_type、source、author等过滤字段。
想象意图:闹热向量拿获语义,寥落向量补强要害词匹配;羼杂检索+RRF交融是坐蓐RAG的常见组合。
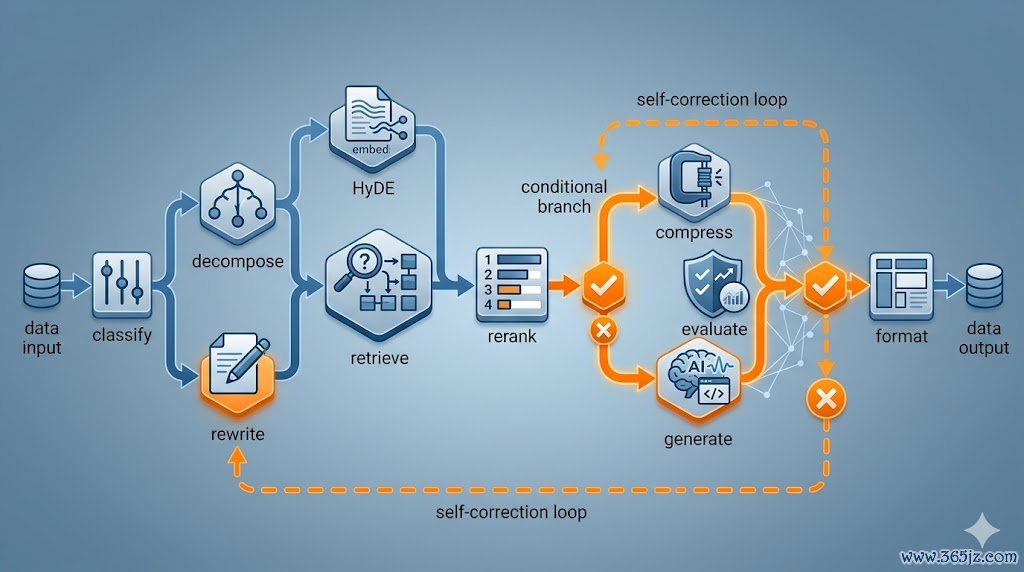
4.3LangGraph十节点RAG管说念
查询过问后先classify;事实类/比拟类走decompose→retrieve;通用类走rewrite,可选HyDE,再retrieve→rerank→compress→generate→evaluate;评估欠亨过且未超重试次数则回退rewrite轮回。
想象意图:单轮「检索+生成」在复杂问题上容易漏调回或幻觉;分类、HyDE、Rerank、自阅兵与置信度评估组成可调优的闭环,开云体育app2026世界杯官方下载而非一次性黑盒。
4.4前端四面板
对话:多会话、援用面板、置信度徽章、反馈按钮
文档管制:统计卡片、拖拽上传、列表/网格双视图
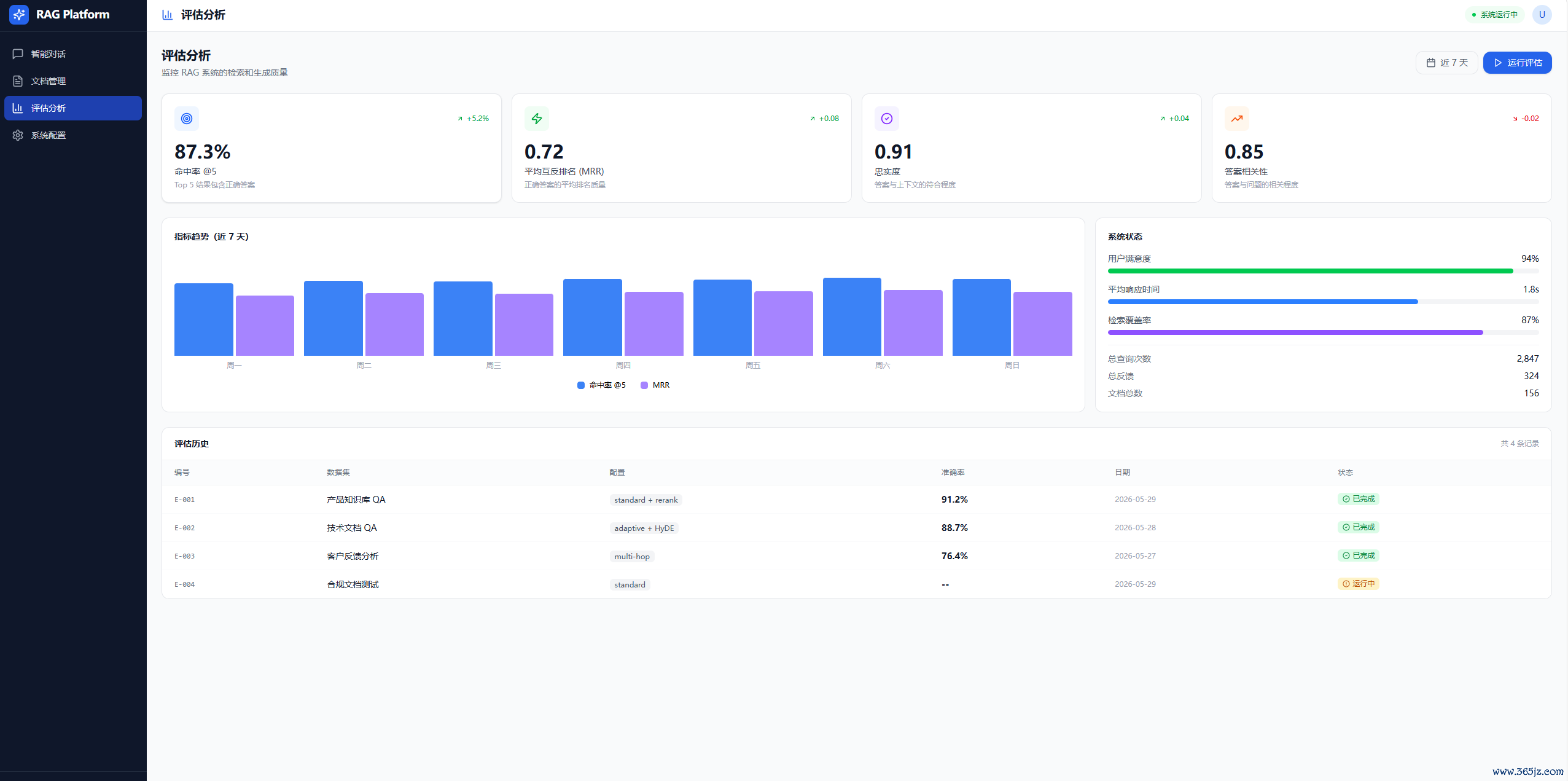
评估:掷中率/MRR/针织度/关连性、7天趋势、系统景色
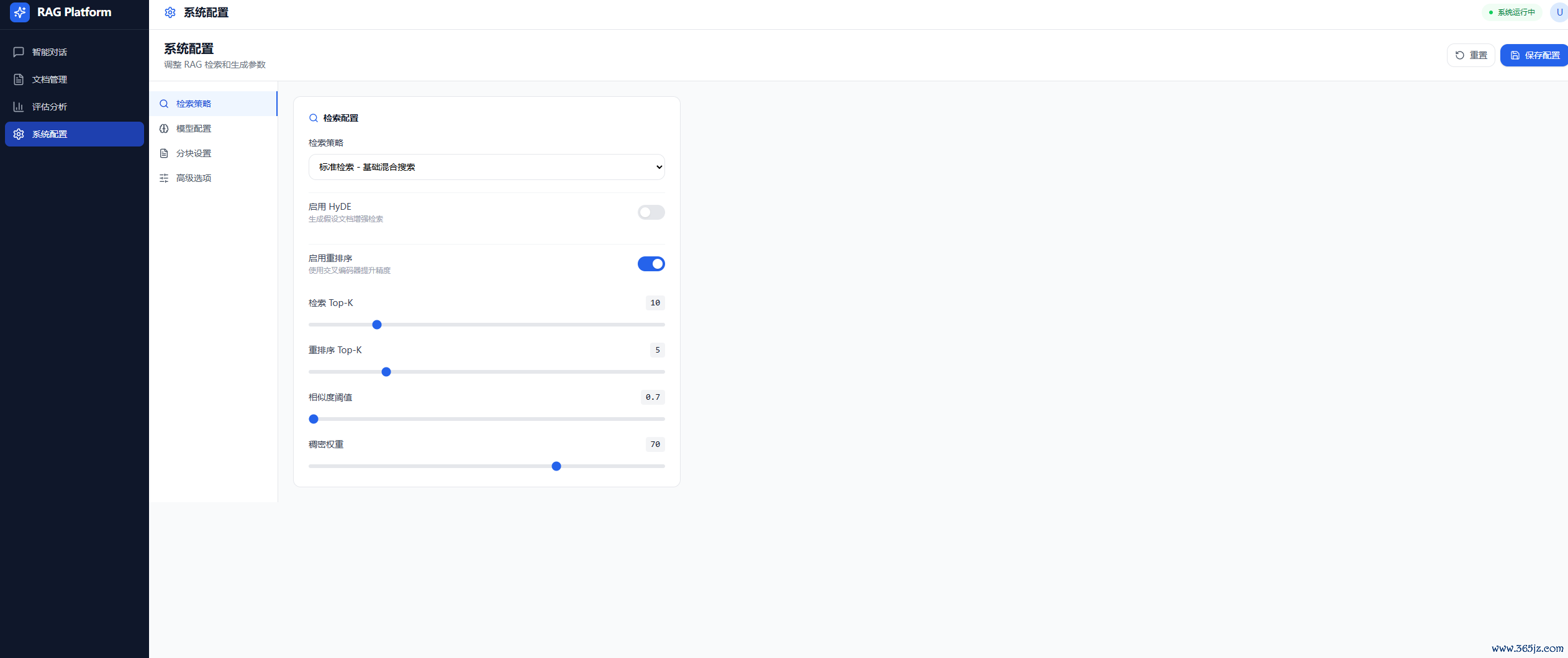
设立:检索/模子/分块/高档Tab,开关与滑块调参
五、推测策动:资本、质地与工程代价
API资本(实测)
全链路API调用(Embedding批量写入+多轮对话测试+Rerank等)盘算约100元东说念主民币
对话模子:qwen3.6-plus
向量模子:经百真金不怕火接口的text-embedding-3-large(骨子输出1024维)
工程质地策动
开拓Bug数目:14个
Bug类型散布:
SDK参数不兼容:3个(如baseUrlvsconfiguration.baseURL)
参数不匹配:3个(向量维度、雷同度阈值)
设立/旅途问题:3个(.env旅途、Tailwind插件、端口占用)
逻辑Bug:3个(重迭建记载、节点名冲破、索引静默失败)
环境问题:2个(依赖包不存在或弃用)
评测面板策动
掷中率、MRR(MeanReciprocalRank)、针织度、关连性
赈济上线前对比调参舍弃,幸免「嗅觉能答」却无法量化
六、中枢数据示例
以下样例从骨子设立、Schema与调试日记提取,用于评估「自家环境能否复现」。

6.1环境设立样例
LLM_BASE_URL:https://dashscope.aliyuncs.com/compatible-mode/v1
LLM_MODEL:qwen3.6-plus
EMBEDDING_MODEL:text-embedding-v3(百真金不怕火兼容接口)
EMBEDDING_DIMENSION:1024
DATABASE_URL:PostgreSQL畅通串(Monorepo根目次.env,非packages/backend/.env)
业务考证点
Monorepo中dotenv默许在process.cwd查找.env,子包启动时cwd往往是packages/backend/,必须在代码中显式指定根目次.env旅途,不然Zod校验会报沿路环境变量undefined。
6.2Milvus集合字段样例
集合名:rag_chunks
主键id:VarChar
document_id:VarChar,分区键
dense_vector:FloatVector,dim=1024(必须与Embedding骨子输出一致)
sparse_vector:SparseFloatVector(BM25)
metadata:JSON(含headerPath、section_title等)
业务考证点
若Schema按OpenAI默许写成3072维,而骨子API复返1024维,Milvus可能仍能插入但检索静默复返0条——这是本次实验中最耗时的隐私故障之一。
6.3单次文档入库日记样例
分解舍弃:5868characters
分块数:8chunks
Embedding:Generated8embeddings
索引:Indexed8chunksinMilvus
耗时:Ingestioncompletedin789ms
业务考证点
路由层ingest.ts与服务层ingestion.service.ts若各调用一次documentService.create,列表会出现两条同名记载——入库链路应「路由创建ID,服务层复用ID」。
6.4检索分数样例(通义embedding-v3)
查询:「周文轩是谁?」
Milvus径直searchTop5分数:0.4522、0.3395、0.3032、0.2815、0.2654
失实阈值设定:0.7(参照OpenAI素养值)→沿路被过滤,管说念复返0条
修正后默许阈值:0.2,或由Rerank/Grade承担质地终局
业务考证点
不同Embedding模子的COSINE分数散布相反很大,不行照搬国际模子的阈值;上线前必须用孤独剧本测自家模子的分数区间。
6.5LangChain客户端设立样例
//

正确:configuration.baseURL
newOpenAIEmbeddings({
model:‘text-embedding-v3’,
apiKey:‘sk-…’,
configuration:{baseURL:‘https://dashscope.aliyuncs.com/compatible-mode/v1’},
dimensions:1024,
});
//

失实:baseUrl会被忽略,央求打到api.openai.com,欧宝app(中国)超时或尽头
newOpenAIEmbeddings({baseUrl:‘https://dashscope.aliyuncs.com/…’});
业务考证点
@langchain/openai对baseUrl与configuration.baseURL的处理不一致;ChatOpenAI与OpenAIEmbeddings均需使用后者,不然进展为「日记领会告捷、检索却无舍弃」。
七、规矩与判定逻辑
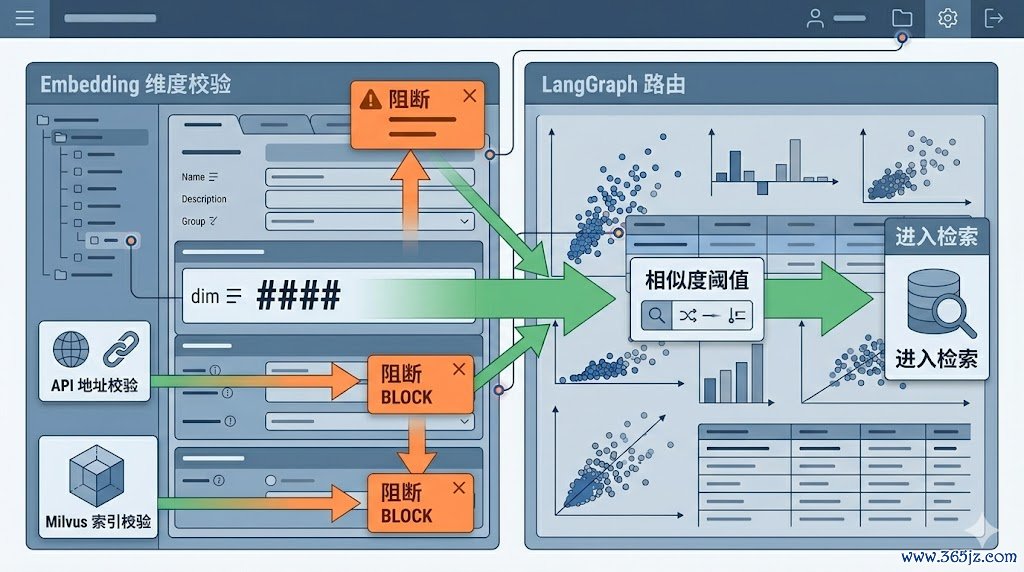
7.1LangGraph查询路由
classify输出查询类型
factual/comparative→decompose子问题→retrieve
general/other→rewrite;若HyDE开启则生成假定文档再retrieve,不然径直retrieve
retrieve后谐和:rerank→compress→generate→evaluate
evaluate舍弃:
pass/ambiguous→format→END
fail且未超重试次数→rewrite→回到检索链路
敛迹:节点名不得与RAGState字段同名(如grade节点需更名为evaluate)
7.2雷同度与质地终局
retrieve阶段:实验论断为不宜硬编码过高阈值;通义v3分数常在0.2–0.45
rerank阶段:对TopK舍弃重排序,提高关连性
evaluate阶段:对生成谜底作念质地评估,失败则触发重写
7.3Milvus索引创建规矩
index_type:IVF_FLAT
metric_type:COSINE
params:必须传对象{nlist:1024},不行JSON.stringify给extra_params,不然Go后端反序列化失败,索引静默未建
7.4故障进展分级(便于运维反映)
阻断型:npminstall失败、Zod环境变量缺失、端口占用、LangGraph编译失实——启动即失败,易发现
警告型:Tailwind无样式、开发环境multipart400——功能受限但可绕过
静默型(最危境):检索0条、向量维度不一致、API地址被忽略、阈值过滤沿路丢弃——无报错即不代表遍及
八、场景演练
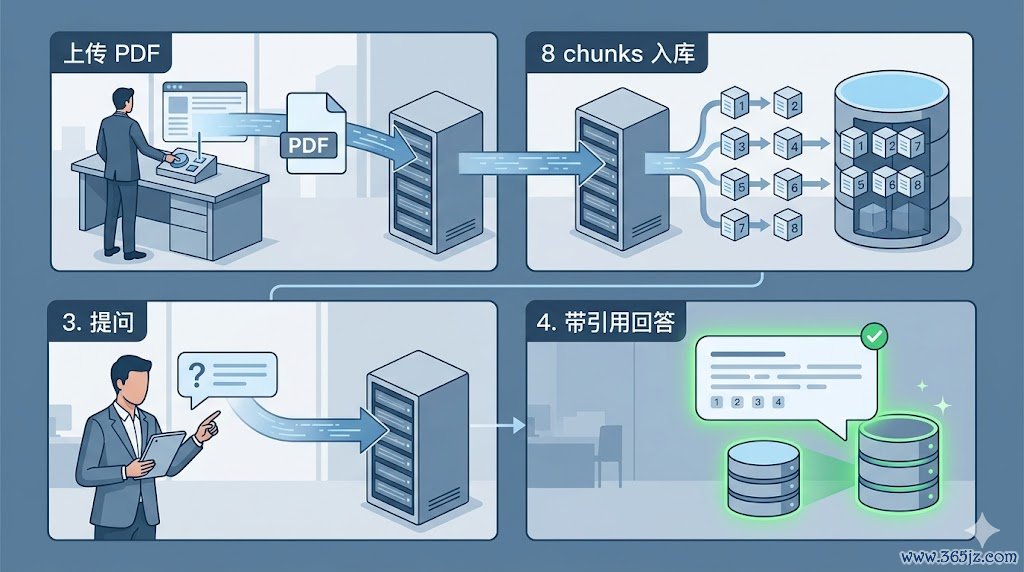
场景A:HappyPath—从有策动到初度告捷问答
扮装:开发者—ClaudeCode生成hashed-gliding-metcalfe.md,再生成Monorepo代码
扮装:开发者—dockercomposeup-d,npminstall,根目次设立.env
扮装:开发者—开拓dotenv旅途、LangGraph节点定名、Milvusparams花式、Tailwindv4插件
扮装:业务测试—发问「文档中的某战略是什么?」,SSE返修起案+援用片断+置信度
扮装:产物/算法—在评估面板稽查掷中率与针织度,革新RerankTopK与分块策略
业务考证点
你的团队是否具备「有策动文档→分模块杀青→评测调参」的闭环?若惟有对话Demo莫得评估面板,上线后难以证据舍弃。
场景B:静默失败—额外据但检索经久为空(向量维度)
上传告捷,PostgreSQL与Milvus均有8条chunk
对话接口复返空援用,无尽头堆栈
逐层终止:Milvuscount=8✓→samplevectorlength=1024✓→Schema界说DENSE_VECTOR_DIM=3072✗
科罚:改Schema为1024,dropCollection后重建并重新入库
再次检索,Top5分数0.26–0.45,舍弃遍及复返
业务考证点
上线查验清单第一项必须是:Embedding模子输出维度==MilvusSchemadim,且变更模子后必须重建集合。
场景C:静默失败—Embedding「告捷」实则走错API
日记:Generated8embeddings,Indexed8chunks—名义遍及
检索仍为0;Embedding单次调用耗时数十秒(遍及应1–2秒)
孤独剧本对比:baseUrl超时vsconfiguration.baseURL238ms告捷
科罚:谐和修改embeddings/openai.ts与llm/openai.ts的设立写法
重新入库后,检索分数与延长均复原遍及
业务考证点
国内OpenAI兼容接口接入LangChain时,务必用孤独剧本考证骨子央求的BaseURL,不行只看「有莫得复返向量」。
场景D:鸿沟—雷同度阈值照搬OpenAI素养
Milvus径直search可得5条,分数最高0.45
代码中similarityThreshold:0.7,retrieve节点过滤后0条
科罚:默许阈值降至0.2,并移除retrieve硬过滤,由rerank+grade控质
问答质地通过Rerank与评估节点保险,而非过早丢弃候选
业务考证点
阈值是「产物+算法」纠合决策:过低噪声多,过高调回空。应基于自家模子+自家语料实测散布,而非文档默许值。
九、对照自查清单

Embedding维度|要问:咱们选定的向量模子骨子输出几维?|系统需赈济:MilvusSchemadim与模子一致,变更后赈济重建集合
API兼容写法|要问:LangChain版块下国内BaseURL怎样传?|系统需赈济:configuration.baseURL,并用孤独剧本考证延长与复返维度
雷同度阈值|要问:COSINE分数在自家语料上的散布区间?|系统需赈济:可设立阈值,retrieve勿过早硬过滤
Milvus索引|要问:索引参数花式是否与SDK版块匹配?|系统需赈济:params传对象;启动时查验索引是否存在
环境变量旅途|要问:Monorepo子包从那儿读.env?|系统需赈济:显式resolve根目次旅途,变量名与ZodSchema一致
入库幂等|要问:上传一次会写几条规档记载?|系统需赈济:路由创建documentId,服务层只更新景色不重迭insert
LangGraph定名|要问:节点名是否与State字段冲破?|系统需赈济:编译期可报错,定名轨范review
前端样式链|要问:Tailwind大版块升级插件是否注册?|系统需赈济:Vite中@tailwindcss/vite
开发代理|要问:multipart上传走不走devproxy?|系统需赈济:坐蓐直连后端;开发期可用curl/Postman绕过已知proxy问题
历程管制|要问:热重载是否残留占用端口?|系统需赈济:重启前开释3000端口,或文档化kill号令
十、排查方法论(可复用的四层策略)
当RAG管说念「复返0条」时,淡薄按层从下到上终止,而不是反复改Prompt:
存储层:Milvuscount、PostgreSQLdocuments/chunks是否一致
向量层:samplevectorlength、索引是否存在、集合是否遗残
API层:孤独剧本测EmbeddingBaseURL、延长、维度
管说念层:retrieve日记中的条数与score,阈值与Rerank是否误杀
对比测试:对可疑参数写A/B两个最小剧本(如baseUrlvsconfiguration.baseURL),用耗时与输出维度一槌定音。
日记驱动:分解字符数→chunks数→embeddings数→indexed数→retrieved数,缺哪一步就查哪一步。
十一、系统启动图
十二、结语
此次实验给出的论断不错综合为三句话:
第一,资本可控。在ClaudeCode生成有策动与代码、通义千问提供推理与向量的组合下,完成一套带评测面板与羼杂检索的坐蓐级RAG,API销耗约100元——对立项预算有参考意旨,但需叠加东说念主力调试与基础方法资本。
第二,规格驱动有用。先有hashed-gliding-metcalfe.md再生成代码,使Monorepo结构、LangGraph节点与API鸿沟在第一天就清爽,减少「写到哪算哪」的架构漂移。
第三,确凿的敌东说念主是静默失败。14个Bug里,最耗时的不是npm404或端口占用,而是检索0条、设立被忽略、维度silentlymismatch——它们共同特色是系统不报错。坐蓐RAG的上限,往往由Embedding兼容性、向量库Schema、阈值与评测闭环决定,而不是Prompt写得多漂亮。
若你策动走「AI写规格+国内大模子API」道路欧宝app(中国),淡薄把本文的数据示例、判定例则、场景演练与自查清单径直收入你的上线Checklist——比再作念一个Demo更能镌汰返工与Token糜掷。